

Wordle Starter Words
TL;DR
I am going to put the “Jump To Recipe” button right at the top. The objective is to find a set of words that may be used as Wordle starter words that accomplish two things:
- Possibly guess the word of the day on the first attempt.
- Eliminate as many words as possible with the first guess to decrease the number of guesses needed.
My analysis contains two main assumptions:
- Words where letters are repeated (e.g., GOOFY) are ignored since they add limited value in subsequent guesses.
- Past winning words will not be featured again (As of January 24, 2026 Wordle has not had a winning word repeat in another game).
Here are two words I deduced as a good starter words (as of January 24, 2026):
- SALON
- SANER
Data Insights
- Focus on words that start with ‘S’. The letter ‘S’ is the first letter of around 14.6% of the previous winning words; the next closest is ‘C’ at around 8.5%.
- Ignore words that end with ‘S’. It is the last letter in only around 1.5% of previous winning words. Although when looking at all five-letter words, around 22% end in ‘S’. I suppose you can say the name of the game is Wordle, not Wordles.
- Common words constitute the winning word around 40% of the time.
- ‘A’ is the second letter in around 18.7% and included overall in around 10.8% of all five-letter words.
- ‘E’ is the fourth letter in around 16.1% and included overall in around 9.7% of all five-letter words.
Methodolgy
To conduct an analysis, I needed to gather data on all five-letter words in the English language, load it into a database, and then organize, analyze, validate, and visualize the data. Database tables and queries are also available on GitHub.
Gathering Data
I was able to retrieve all needed data from the three open sources listed below.
All Words
A text file containing 479,000 English words may be found here.
Common Words
This list of 10,000 common words is a widely referenced dataset, often attributed to Eric Price at MIT, it provides a plain text list of frequently used English words. It is frequently used for testing, natural language processing, and generating random words. The list is ordered by frequency and includes foundational vocabulary.
Words That Were Previously Featured
Past Wordle answers: An archive of previously used words in Wordle.
Data Analysis Tools
The process involved using the following tools.
SQL Database Tables
In order to analyze the data, I created three database tables:
- Table Containing All Words: I loaded the entire English word file into a SQL database, but focused only on the subset of 15,921 five-letter words.
- Common Words: Of the 10,00 common words in the file, 1,379 are five-letter words. All 10,000 were loaded into a database table.
- Past Wordle Answers: As of January 24, 2026, there are 1,680 previous answers loaded into my database table.
SQL Queries
I focused on extracting data along the following factors:
- Winning words: I extracted the first, second, third, fourth, and fifth individual letters from all of the past 1,680 winning words and grouped them by frequency.
- All English words not including previous winning words: I extracted all words except winning words along the same parameters to obtain the count of every letter by its position within the word.
Additionally, I compared the set of common words to the set of previous winners. Out of the 1,680 winning words, 672 were identified as common words, 40% of winning words are included in the common word data set. That leaves 707 common words that have yet to be the winning word.
Google Sheets
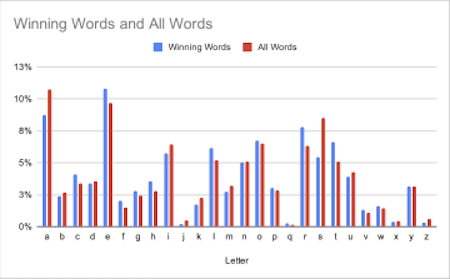
I then upload all extracted data to Google Sheets for visualization. The first two tables illustrate how often each letter of the alphabet appears in each letter position for all words (Figure 1) and winning words (Figure 2). The last table compares the letter distributions for all words and winning words.
Figure 1. All words with previously winning words excluded.
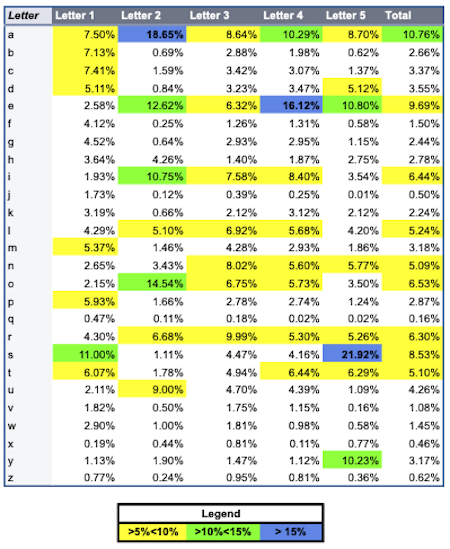
Figure 2. Only winning words.
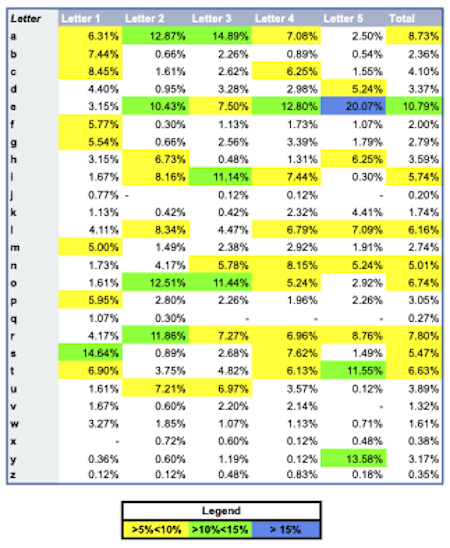
Figure 3. Comparison of the two sets.
Data Review
Looking at the visualizations, there are some meaningful observations.
- 'A' and 'E' are the most frequently appearing vowels in both sets.
- 'A' is underrepresented in the winning words, particularly in the second letter position.
- 'E' is overrepresented in the winning words, particularly in the fifth letter position.
- As noted at the start, words ending in 'S' are rarely the daily Wordle. However, words beginning with 'S' are the most common in both data sets.
Focus Areas
I decided to search for two distinct data sets.
First, a set of words which are aimed at guessing the word on the first guess. I included only common words and all of the letters highlighted in figure one above (All words minus winners, letters in positions with a greater than 5% frequency).
Word Set Focused on Solving on First Guess
Search Criteria:
- Letter One contains('a','b','c','d','m','p','s','t')
- Letter Two contains('a','o','e','i','u','r','l')
- Letter Three contains('a','e','i','l','n','o','r')
- Letter Four contains('a','e','i','l','n','o','r','t')
- Letter Five contains('a','d','e','n','r','t','y')
- Exclude previous winning words.
- Exclude words containing letters that are contained in the word more than once.
- Include only common words.
Since it is random, all of these words yield about the same chance at solving in the first word (slim, maybe 1:1,000 if the assumptions are correct). I personally go with SALON since it begins with 'S'. Who knows though, there are killjoys out there that start with ADIEU every day, no fun. Also some of the words in the list appear to be proper nouns and may not be accepted by Wordle, that makes the odds even better! It also illustrates that even with large data sources, information still requires human judgment. Wordle writers can be cruel, but it is doubtful they are going to include BRIAN as their daily word.
Second, a set of words which are aimed at eliminating as many words as possible while still having a slight chance to guess the word on the first try. For this data set, I searched for all words that begin with 'S' and contain the two most frequent vowels, 'A' and 'E'. For the vowels, I wanted to look into the two blue spaces in the first figure above, ‘A’ in position 2 and 'E' in position 5. For the remaining two positions, I opted to use the four most frequently appearing consonants overall.
Word Set Focused on Eliminating Words
Search Criteria:
- First Letter: 's'
- Second Letter: 'a'
- Third Letter: ('r','l','t','n')
- Fourth Letter: 'e'
- Fifth Letter: ('r','l','t','n')
Since 'N' is underrepresented by about 2.2% in previous winners, I feel it is SANER to go with option two.
Roadmap... Maybe
I had a lot of fun putting this together and hope others also find joy in reading this. Should I opt to keep it up, there are a few things I would do.
- Validate that words generated in each data set are accepted by Wordle as valid.
- Create a table of only Wordle words, then link Common and Previous Winners as foreign keys to it
- Already done, set up a POST API to push the Wordle result each day.
- Set up a js to update the text area showing the common words that have not previously won.
- Run a daily simulation to see how many words each of these eliminates each day.
- The Wordle bot shows how many words are left after each selection. I can leverage this tool to help validate my data sets.
- Dig a bit deeper into letters who appear significantly more regularly in winning words than in total words. Maybe it is the difference in data sets.
- Also dig deeper into letters who appear significantly less in winning words. Maybe these should given a higher priority as the set of winning words will deviate toward the mean.